



Legal AI & Workflow Automation for Improving Legal Operations
Combine the power of legal AI + workflow automation — responsibly.
Save time and automate work with the ndMAX suite of tools that brings generative AI to your content so you can get the most out of AI and see concrete results and immediate ROI within the trusted, comprehensive security and guardrails of the NetDocuments platform.

Rather than taking your content to AI, we are bringing AI to your content.
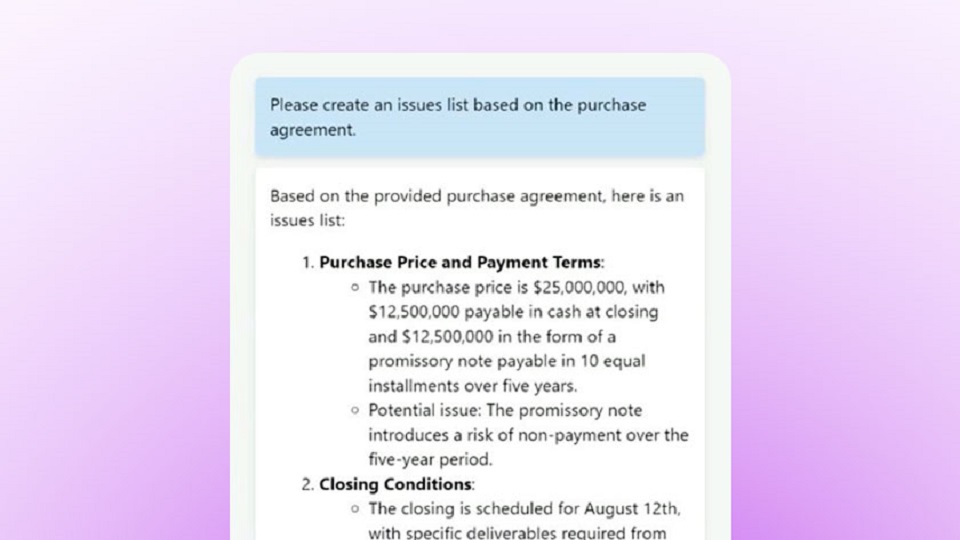
Get instant answers & insights
Getting started with AI for legal is easier than you think. The ndMAX Legal AI Assistant lets you tap into the knowledge within your documents in a conversational way. Ask a question of one or hundreds of files — get instant answers.
Build custom legal AI apps
The ndMAX AI App Builder gives you flexible tools to be able to create AI apps tailored to your unique workflows, practice areas, and jurisdictions. Also easily customize pre-built legal AI apps available in the ndMAX Studio.
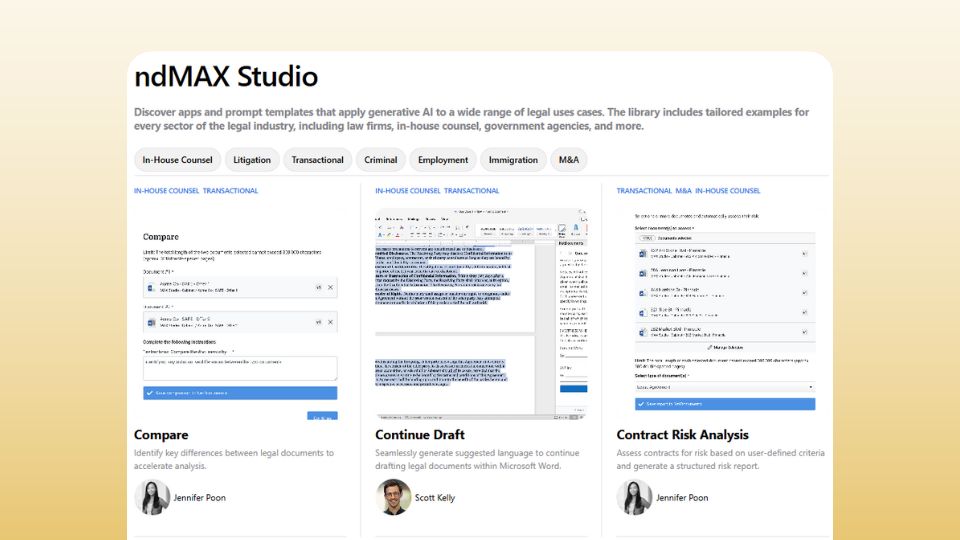
Use ready-to-go legal AI apps
Within the ndMAX Studio, the go-to hub for AI and automation for legal work, access AI apps for multiple legal use cases, educational videos, and demos to help you get the most out of AI.
on-demand webinar
The Hidden Costs of Outdated LegalTech: Understanding the gaps – and how to fix them
Save time & boost productivity
Built-in legal AI and automation puts problem-solving power at your fingertips. Whether you need quick answers to questions or large-scale, complex automations, ndMAX helps you get the job done fast — without jumping into a separate platform or finding yet another vendor. With ndMAX, you can securely leverage your documents, your data, and your expertise to create smart, time-saving solutions.


See day-one value
Get immediate results with the Legal AI Assistant and ready-to-go legal AI apps from the ndMAX Studio, the go-to hub for AI and automation for legal work, with AI apps for numerous legal use cases across multiple practice areas to help you get the most out of AI with things like translation, summarization, and playbook analysis.
Maintain control of your data
Protecting intellectual property and confidential client data is no small task. That’s why NetDocuments brings AI to your content instead of requiring documents be taken outside the security of the cloud document management system (DMS). And have confidence knowing your data is not retained, reviewed by others, or informing the large language model (LLM).


Tap into Microsoft AI
Powered by Microsoft Cognitive Services and Azure OpenAI, ndMAX AI for legal brings AI capabilities into the Microsoft 365 applications you use daily — all while keeping your sensitive information secure and confidential.
Our Approach to AI

DISCOVER a BETTER WAY TO Work
See why legal professionals are trying ndMAX AI-powered tools.
Automated Workflows
Turn complicated processes into painless automations so you can check off tedious tasks without lifting a finger.
Quicker Answers You Can Trust
The Legal AI Assistant can analyze hundreds of your documents in mere seconds, so you find the answers to your questions faster.
Instant Value & ROI
Put our ready-to-go AI apps to work on day one and experience the benefits of secure legal AI right away. Watch demos and access educational resources to ensure you can get the most out of AI.

Trusted Security
Enjoy the benefits of AI without exposing your confidential data to unauthorized eyes — be they human or machine.

customer stories
See what customers are saying…

“The tools already respect our client and matter based security and ethical walls…”
Jeff Sabado, Director of Knowledge Management
Davis Wright Tremaine
“We’re really excited about what we can do with [the AI App Builder’s] ability to create apps that can analyze any sort of draft document and provide comments based on our firm’s playbook. This should allow us to scale our unique expertise and access new clients with a brand new product.”

Charly Duffy
Coghlan Duffy
“We were able to calculate that this app could save over 1,500 hours of work a year while at the same time producing a better work product. So that was a no brainer for us.”

Jared Gullbergh
Buchanan
FAQs
What capabilities are available within the ndMAX suite?
ndMAX includes the Legal AI Assistant for querying documents, App Builder for building and customizing apps, and the ready-to-use Legal Apps.
What large language model (LLM) is used by ndMAX?
ndMAX is powered by Microsoft Cognitive Services and Azure OpenAI, and their suite of OpenAI models. As soon as new models are made available, NetDocuments tests them internally and makes them available for use. However, because generative AI is a new and rapidly developing technology, our solutions are designed to be model agnostic, so if better models are developed, they may be used.
What information is shared with or used to train the LLM?
Only the inputs and outputs are shared with or used by the LLM. They are not maintained beyond the exchange of information to produce the output and are not used to train the LLM. Additionally, because legal work frequently involves sensitive topics, NetDocuments has an agreement with Microsoft that prevents our customers’ content from triggering their abuse monitoring systems.
Can the Legal Apps be customized?
Yes, while designed to be ready-to-use, the Legal Apps were created using the ndMAX App Builder, so they may be customized to the specifications needed by your firm, clients, practice area, or jurisdiction.
Does the ndMAX App Builder require a developer to do customizations or build apps?
The ndMAX App Builder is a low-code document and workflow automation system designed to be leveraged by those who understand the processes involved, so developers are not necessary. Our Legal AI Apps are purpose-built so you don’t have to have internal development resources to get value on day one. If you prefer to outsource the development of your own legal apps, we have partners that are certified in building apps using the App Builder.
Resources
Level up with these resources
-

- eBook/Whitepaper
Lawyers Weekly Legal Tech Guide 2026
AI is transforming the legal industry — and it’s happening now.…
-

- eBook/Whitepaper
1-Minute Guide to Why an Intelligent DMS Matters Now
Leaders in legal are rethinking the role of their document management…
-

- eBook/Whitepaper
Lawyers Weekly In-House Guide 2025
Your guide to smarter, faster, and more strategic in-house legal operations.…
-

- Webinar
Time to take control of your firm’s documents – the how and why of document management for SME firms
Discover the essential steps for SME law firms to stay competitive,…
NETDOCUMENTS