


report: Context Graph for Legal
What Is a Legal Context Graph? And Why Legal AI Agents Need One

Scott Kelly
Vice President of Product and AI Strategy
Legal AI has a context problem
Legal AI does not fail only because a model gets a sentence wrong. It fails when it does not understand the work it has been asked to help with. It does not know the matter history. It does not know which precedent actually matters. It does not know who negotiated the clause, whether the client has restricted use of AI, whether an ethical wall changed yesterday, or why one document matters more than another.
In legal work, those details are not background information. They are the work.
For years, law firms and legal teams have lived with a knowledge problem hiding in plain sight. A new associate joins a complex matter and spends days reconstructing context that already exists somewhere in the firm. A partner asks whether the firm has handled a similar issue before, and the answer depends on who happens to be in the room. A senior lawyer retires, and decades of judgment, precedent, and practical knowledge become harder to reach.
That arrangement worked when people were the only consumers of the firm’s knowledge. The system of record captured the work product. Governance protected it. Experienced lawyers carried much of the rest in their heads.
AI changes the equation. Lawyers are no longer the only consumers of legal knowledge. AI assistants, agents, and emerging autopilots now need to work with that knowledge too. And an agent that cannot reach the right context is working blind.
The next layer of legal AI is not another chatbot. It is a governed legal context layer: a structured, queryable, permission-aware representation of the matters, documents, people, communications, activity, and legal concepts that make up the firm’s institutional knowledge.
What is a legal context graph?
A legal context graph is a live, governed map of legal work. It connects the documents in a firm with the matters they belong to, the people who worked on them, the communications around them, the activity that changed them, the legal concepts inside them, and the permissions that control who can use them.
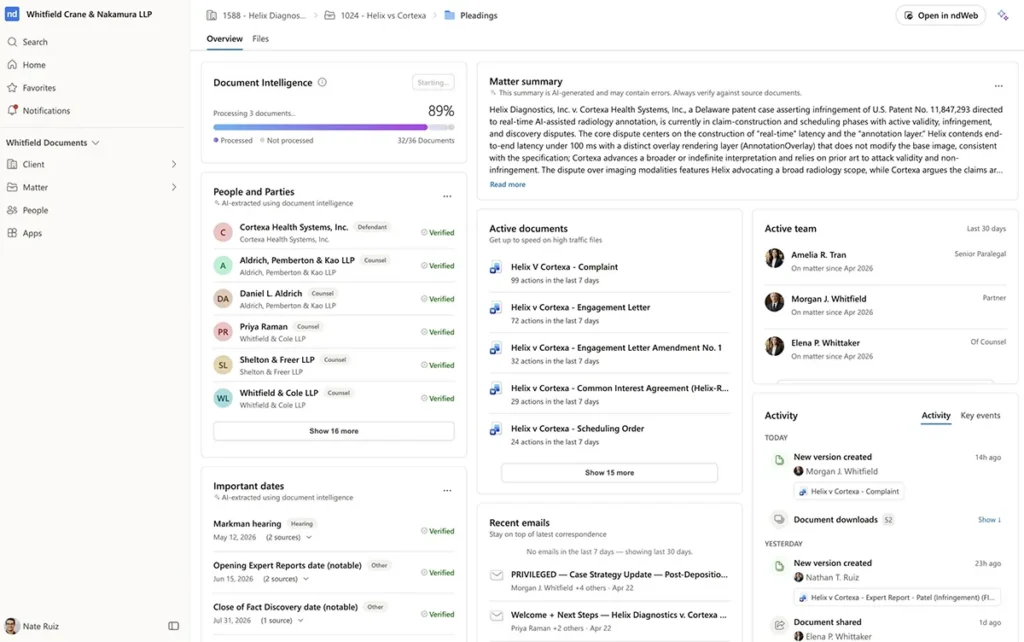
That matters because lawyers do not think about work as isolated files. They think in matters, parties, issues, clauses, timelines, witnesses, negotiations, strategy, precedent, and risk. AI agents need to reason from the same context if they are going to be useful.
A document management system has traditionally answered an important question: where is the document? A legal context graph answers a different one: what does this work mean, how is it connected, what matters right now, and what is this person or agent allowed to know?
From taxonomy to context graph
Legal AI needs more than a pile of documents. It needs layers of structure.
A taxonomy (for example, emerging industry standards like FOLIO, NOS Legal, and LMSS) gives the system a consistent way to classify legal work and extract the metadata that matters for each category. Once the system knows a document is an NDA, lease, complaint, or merger agreement, it knows what fields to look for: parties, dates, governing law, obligations, claims, clauses, courts, judges, or other practice-specific details.
An ontology defines how those concepts relate. Matters have parties. Parties have roles. Contracts contain clauses. Clauses create obligations. Courts have judges. Claims arise under statutes. The ontology is the blueprint for how legal concepts fit together.
A knowledge graph connects the actual things in the firm: this matter, this client, this agreement, this counterparty, this judge, this clause, this prior negotiation, this lawyer with relevant experience.
A context graph adds what legal work depends on most: what matters right now. It knows which documents changed recently, which matter is heading to mediation, which people are active, which prior work is relevant, who has access, and which policies or ethical walls govern the answer.
The difference is like a static map versus a real-time navigation system. A static map shows the roads and intersections. A navigation system knows where things are, what route is available, what traffic or roadblocks exist, and what has changed since the last time you looked. For legal AI, that real-time context is the difference between an agent that searches documents and an agent that can help with legal work.
AI Profiling is one of the ways NetDocuments builds that foundation. It turns unstructured legal documents into structured legal data: document classifications, extracted metadata, clause types, parties, jurisdictions, governing law, dates, obligations, and other concepts that can be connected across matters. But the goal is not metadata for metadata’s sake. The goal is context that a lawyer, search experience, or AI agent can use at the moment work is happening.
| The progression in one view | |
| Taxonomy | Classifies the work and guides what metadata should be extracted for each document or matter type. |
| Ontology | Defines how legal concepts relate: matters have parties, contracts contain clauses, clauses create obligations. |
| Knowledge graph | Connects the actual entities and records: this matter, this client, this agreement, this judge, this lawyer. |
| Context graph | Adds the live legal context: what changed, what matters now, who has access, what policy applies, and what an agent needs before acting. |
The three foundations of a legal context graph
1. Documents become structured legal data
Legal documents without structure are a wall of text. Drop a legal AI agent into a matter with hundreds or thousands of unstructured documents, and it has to read its way into understanding every time it is asked to help. A human reviewing the output pays the same cost in reverse.
AI Profiling changes that. Instead of treating documents as static files, the system extracts the legal facts and concepts that make them useful: effective dates, governing law, jurisdiction, parties, counterparty, judge, clause types, obligations, renewal terms, termination rights, and whatever practice-specific fields a firm needs.
That extracted structure compounds. Profile a document once, and every later search, matter overview, report, and agent workflow can use the result. Two firms may have the same documents and access to the same models. The firm with structured, governed, consistently extracted legal context will get better AI outcomes.
2. Search works by meaning, not just keywords
Lawyers often know the concept they are looking for before they remember the words used to express it. A transactional lawyer may need a precedent with a similar-products carveout, even if the document she needs uses different language. A litigator may remember the issue but not the exact phrase in the brief.
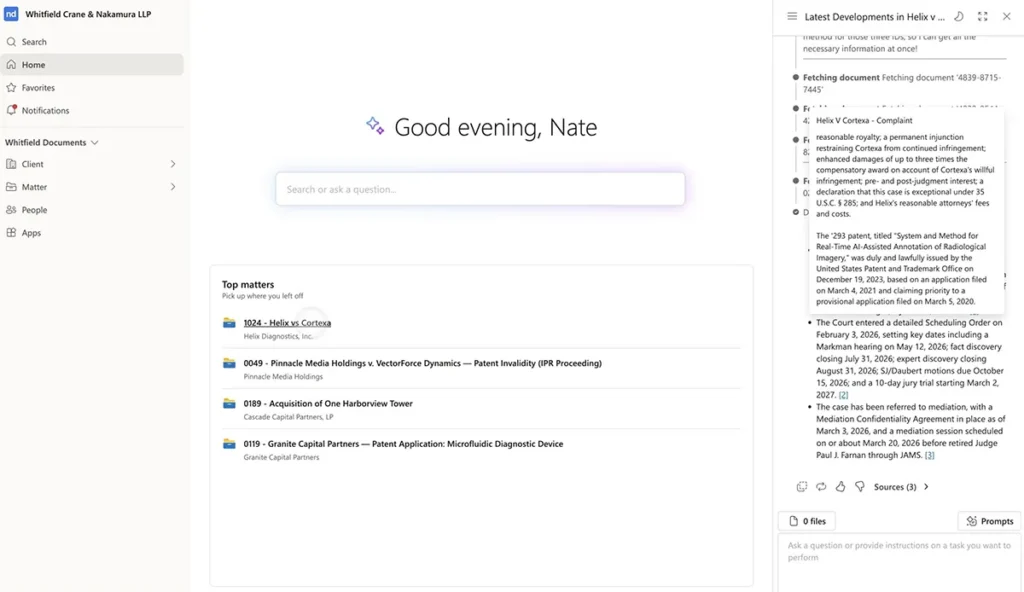
Keyword search still matters. Party names, case numbers, statute citations, and defined terms require precision. But keyword search alone cannot retrieve legal meaning when the words change.
The better approach is hybrid search: lexical search for exact terms, semantic search for conceptual similarity, and metadata filters to keep the results grounded in the right matter, date range, jurisdiction, document type, or practice context.
For lawyers, that means searching the way they think. For legal AI agents, it means retrieving the right context without flooding the prompt with irrelevant material. Better retrieval means less context pollution, fewer missed precedents, and more useful AI output.
3. The matter becomes more than a folder of documents
A matter is not just a workspace. It has a shape. Parties and roles. Claims and defenses. Deal stage or procedural posture. Key dates. Witnesses. Issues. Strategy. Recent activity. Relevant precedent. People who have done similar work before.
Today, much of that context is scattered across documents, emails, spreadsheets, notes, time entries, audit trails, and lawyers’ memories. The context graph brings those pieces together as queryable nodes and relationships above the document foundation.
That is what lets a lawyer open a matter and see the picture that usually has to be reconstructed manually: who is involved, what has changed, what documents matter, what the firm has done before, and where attention should go next.
For a legal AI agent, this changes the economics of the work. Without the graph, every time an agent starts working it has to rebuild context from scratch. With the graph, the agent can begin from the matter’s structure and move efficiently to the information that matters.
Why context has to persist beyond a session
Most AI tools operate on whatever a user gives them in the moment: a set of uploaded documents, a search result, a prompt, or a single session’s context window. That can be useful, but it is not how legal work actually works.
Legal work is cumulative. The most important context may come from a prior matter, a redline from six months ago, an email thread, a partner’s earlier decision, an ethical wall, or a client guideline that changed last night. Uploading a few documents into a session does not solve that problem.
A legal context graph is different because it lives where the work already lives. It is built into the system of record, connected to the firm’s institutional knowledge, and governed by the same permissions, ethical walls, and client restrictions that govern the work itself.
Why building this for legal is hard
This is easy to describe and hard to engineer.
Legal data is mostly language, not clean database fields. The meaning is nuanced. A clause can look ordinary until the exception changes the risk. A matter can turn on a relationship between a pleading, a deposition, an email, and a prior decision. The same concept can be expressed dozens of ways across firms, practice groups, jurisdictions, and document types.
The scale is also different. Large law firms and legal departments do not have ten thousand documents. They have millions or hundreds of millions of records, with permissions, ethical walls, client restrictions, and activity that change continuously.
To make a legal context graph useful, the platform has to extract structure from unstructured documents, index content for both exact and conceptual retrieval, connect records across matters and communications, enforce governance in real time, and make the result available to both lawyers and AI agents without creating uncontrolled copies of the firm’s data.
That is why NetDocuments worked closely with AWS and Elastic on the infrastructure required to index, retrieve, and connect legal context at legal scale. The challenge is not merely building a demo that works on a small corpus. The challenge is making it work across the governed, high-volume, high-stakes reality of modern legal practice.
Built for legal scale means more than storing more documents.
It means extracting structure from unstructured legal language, combining lexical and semantic retrieval, connecting matters and communications, enforcing permissions at query time, and making the result usable by lawyers, agents, and emerging autopilots without creating uncontrolled copies of firm data.
| Built for legal scale | |
| Volume | Modern legal organizations operate across millions or hundreds of millions of documents, messages, versions, and matter records. |
| Meaning | The system has to understand legal language, not just file names or keywords. |
| Retrieval | Lawyers need both precision and conceptual recall: exact terms when they matter, semantic matches when the words differ. |
| Governance | Every request has to respect current permissions, ethical walls, client restrictions, and matter policies. |
| Agents | The same context has to serve people and AI agents without copying firm knowledge into disconnected systems. |
The hard part is not drawing the graph. The hard part is keeping it live, governed, useful, and fast enough for the way legal work actually happens.
Why governance has to live at the context layer
In legal, context without governance is not an asset. It is a risk.
A useful AI agent must know more than what information exists. It must know whether this user, in this matter, at this moment, is allowed to use it. That includes document permissions, ethical walls, need-to-know restrictions, outside-counsel guidelines, client-specific AI policies, and matter-level changes that happen after the data was first created.
This is where architecture matters. If an AI tool copies data into its own system, governance becomes a synchronization problem. Every change in permission, policy, or ethical wall has to be reflected somewhere else. In legal, that is not good enough. The Model Context Protocol (MCP) has emerged to meet exactly this need — authenticated, scoped, just-in-time access between AI and a system of record. Through a governed access layer, AI tools inside NetDocuments and external tools can reach the same authoritative context without each creating their own disconnected copy of the firm’s knowledge.
Why NetDocuments is positioned to build it
A legal context graph cannot be bolted onto legal work from the outside. It has to live close to the documents, matters, permissions, activity, and workflows that already define how the firm operates.
That is why the system of record matters. NetDocuments already sits where legal work product is created, stored, secured, searched, governed, and reused. The platform knows the documents. It knows the matters. It knows the permissions. It knows the activity around the work. And with AI Profiling, concept-based search, matter context, and governed access through MCP, that foundation becomes usable by both lawyers and agents.
The strategic point is simple: many AI experiences will begin to look similar at the surface. The quality of the work they produce will depend on the context layer underneath. A drafting assistant, research agent, workflow tool, or autopilot is only as good as the legal context it can reach, and only as safe as the governance it honors.
What this unlocks for lawyers and agents
Every matter starts with context
A second-year associate is staffed on a contract dispute heading to mediation. Today, she may spend the weekend reconstructing the matter: parties, posture, issues, documents, recent communications, and what the partner thinks matters.
With a legal context graph, the matter overview is already there. Not as a static summary, but as a connected view of the matter: parties, timeline, key documents, claims or issues, recent activity, and the people who have done similar work before. The associate still exercises judgment. She just starts from context instead of a blank page.
Search matches the lawyer’s mental model
An M&A partner may not remember the deal name. He remembers the business issue: a tipping basket that flips to first-dollar recovery, negotiated on the company side, in the last sixteen months. The context graph lets search use the concepts, metadata, and matter relationships together, so the system can return the relevant precedent instead of forcing the lawyer to remember the exact words.
Institutional knowledge becomes reachable
Firms have tried to capture institutional knowledge for decades. The problem is that knowledge systems separated from the work tend to decay. The context graph reverses the geometry. The knowledge is built from the work itself: the documents, matters, communications, activity, and outcomes that already live in the system of record.
When a senior lawyer retires, not everything she knows can be captured. Judgment is still judgment. But the matters she shaped, the clauses she negotiated, the strategies she chose, and the work product she left behind can become easier to find, understand, and reuse.
Agents can do more than answer isolated questions
An agent that receives only a few uploaded documents can summarize those documents. An agent connected to the firm’s governed context can do more useful work: find relevant precedent, identify the right starting point, compare a draft against the firm’s playbook, surface related communications, or explain what changed in a matter since the user last looked. That same foundation is what makes autopilots possible: longer-running, multi-step workflows where agents do not simply answer a question, but help move legal work forward over time with the right matter context, permissions, and guardrails in place.
The difference is not just model quality. It is context quality.
AI agents are only as good as the legal context delivered to them. The model matters. The prompt matters. But in legal work, the decisive question is often whether the agent can reach the right context, under the right governance, at the right time.
The system of record becomes a system of understanding
For 30years, legal technology has done a good job storing what lawyers did. The next chapter is about understanding the work well enough to help lawyers do what comes next.
That does not mean replacing legal judgment. It means reducing the friction around context so lawyers can spend more time on judgment, advocacy, negotiation, strategy, and client counsel.
The legal context graph is the foundation for that shift. It turns the system of record into a governed source of institutional knowledge that lawyers and AI agents can use together. It makes the work more findable, more connected, more reportable, and more ready for the agentic workflows that are beginning to arrive.
The future of legal AI will not be won by the tool with the biggest prompt box. It will be won by the platform that can deliver the right legal context, with the right governance, when the work is happening.