


rapport: Kontextschema för juridik
Vad är en juridisk kontextgraf? Och varför behöver juridiska AI-agenter en sådan?

Scott Kelly
Vice VD för produkt- och AI-strategi
Juridisk AI har ett kontextproblem
Juridisk AI misslyckas inte bara för att en modell tolkar en mening fel. Den misslyckas när den inte förstår det ärende som den har ombetts att bistå med. Den känner inte till ärendets bakgrund. Den vet inte vilka rättsfall som faktiskt är relevanta. Den vet inte vem som förhandlade fram klausulen, om klienten har begränsat användningen av AI, om en etisk barriär ändrades igår, eller varför ett dokument är viktigare än ett annat.
Inom juridiskt arbete är dessa detaljer inte bara bakgrundsinformation. De är själva arbetet.
I åratal har advokatbyråer och juridiska team levt med ett kunskapsproblem som funnits mitt framför ögonen på dem. En ny biträdande jurist ansluter sig till ett komplext ärende och ägnar dagar åt att rekonstruera sammanhang som redan finns någonstans inom byrån. En delägare frågar om byrån har hanterat en liknande fråga tidigare, och svaret beror på vem som råkar befinna sig i rummet. En senior jurist går i pension, och årtionden av erfarenhet, prejudikat och praktisk kunskap blir svårare att få tillgång till.
Denna ordning fungerade när människor var de enda som tog del av företagets kunskap. Dokumentationssystemet registrerade arbetsresultaten. Styrningsrutinerna skyddade dem. Erfarna jurister bar på mycket av resten i sina huvuden.
AI förändrar spelplanen. Jurister är inte längre de enda som använder juridisk kunskap. AI-assistenter, agenter och nya automatiserade system måste nu också kunna hantera den kunskapen. Och en agent som inte kanfå tillgång till rätt sammanhangarbetar i blindo.
Nästa steg inom juridisk AI är inte ännu en chattbot. Det handlar om ett reglerat juridiskt kontextlager: en strukturerad, sökbar och behörighetsanpassad framställning av de ärenden, dokument, personer, kommunikationer, aktiviteter och juridiska begrepp som utgör byråns institutionella kunskap.
Vad är en juridisk kontextgraf?
En juridisk kontextgrafär en dynamisk, reglerad översikt över det juridiska arbetet. Den kopplar samman dokumenten på en byrå med de ärenden de hör till, de personer som har arbetat med dem, kommunikationen kring dem, de åtgärder som har ändrat dem, de juridiska begreppen i dem samt behörigheterna som styr vem som får använda dem.
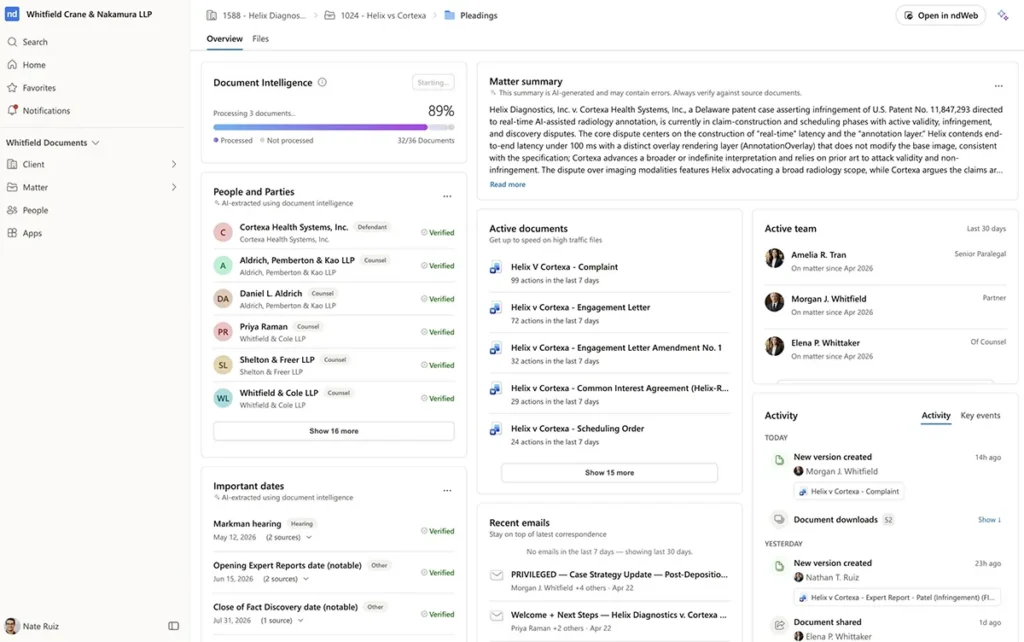
Det är viktigt eftersom jurister inte betraktar sitt arbete som enskilda ärenden. De tänker i termer av ärenden, parter, frågeställningar, klausuler, tidsplaner, vittnen, förhandlingar, strategi, rättspraxis och risk. AI-system måste kunna resonera utifrån samma sammanhang om de ska vara till nytta.
Ettdokumenthanteringssystemhar traditionellt gett svar på en viktig fråga: var finns dokumentet? En juridisk kontextgraf ger svar på en annan fråga: vad innebär detta ärende, hur hänger det ihop, vad är viktigt just nu och vad får denna person eller aktör ta del av?
Från taxonomi till kontextgraf
Juridisk AI kräver mer än bara en hög med dokument. Den kräver flera strukturerade nivåer.
En taxonomi (till exempel nya branschstandarder somFOLIO,NOS Legal ochLMSS) ger systemet ett enhetligt sätt att klassificera juridiskt arbete och extrahera de metadata som är relevanta för varje kategori. När systemet väl vet att ett dokument är ett sekretessavtal, ett hyresavtal, en stämningsansökan eller ett fusionsavtal, vet det vilka fält det ska leta efter: parter, datum, tillämplig lag, skyldigheter, anspråk, klausuler, domstolar, domare eller andra verksamhetsspecifika detaljer.
En ontologi beskriver hur dessa begrepp hänger ihop. Rättsförhållanden har parter. Parter har roller. Avtal innehåller klausuler. Klausuler skapar skyldigheter. Domstolar har domare. Rättsliga anspråk grundar sig på lagar. Ontologin är en modell för hur juridiska begrepp hänger ihop.
En kunskapsgraf kopplar samman de konkreta elementen inom företaget: detta ärende, denna kund, detta avtal, denna motpart, denna domare, denna klausul, denna tidigare förhandling, denna advokat med relevant erfarenhet.
En kontextgraf tillför det som är viktigast i juridiskt arbete: vad som är aktuellt just nu. Den vet vilka dokument som nyligen har ändrats, vilka ärenden som är på väg till medling, vilka personer som är aktiva, vilket tidigare arbete som är relevant, vem som har behörighet och vilka riktlinjer eller etiska gränser som styr svaret.
Skillnaden kan liknas vid en vanlig karta jämfört med ett navigationssystem i realtid. En vanlig karta visar vägar och korsningar. Ett navigationssystem vet var saker och ting finns, vilka vägar som är tillgängliga, hur trafiksituationen ser ut och om det finns några avspärrningar, samt vad som har förändrats sedan du senast tittade. När det gäller juridisk AI är just detta realtidssammanhang skillnaden mellan en agent som söker igenom dokument och en agent som kan bistå i det juridiska arbetet.
AI-profilering är ett av de sätt på vilka NetDocuments lägger denna grund. Den omvandlar ostrukturerade juridiska dokument till strukturerade juridiska data: dokumentklassificeringar, extraherade metadata, klausultyper, parter, jurisdiktioner, tillämplig lag, datum, skyldigheter och andra begrepp som kan kopplas samman mellan olika ärenden. Men målet är inte metadata för metadata skull. Målet är att skapa ett sammanhang som en jurist, en sökfunktion eller en AI-agent kan använda just när arbetet pågår.
| Utvecklingen i ett perspektiv | |
| Taxonomi | Klassificerar arbetet och anger vilka metadata som ska extraheras för varje dokument- eller ärendetyp. |
| Ontologi | Beskriver hur juridiska begrepp hänger ihop: ärenden har parter, avtal innehåller klausuler, klausuler skapar skyldigheter. |
| Kunskapsgraf | Kopplar samman de faktiska enheterna och posterna: detta ärende, denna klient, detta avtal, denna domare, denna advokat. |
| Kontextgraf | Ger en aktuell rättslig bakgrund: vad som har förändrats, vad som är viktigt just nu, vem som har tillgång, vilka regler som gäller och vad en handläggare behöver veta innan hen agerar. |
De tre grundpelarna i en juridisk kontextgraf
1. Dokument omvandlas till strukturerade juridiska data
Juridiska dokument utan struktur är en enda lång textmassa. Om man sätter in en juridisk AI-agent i ett ärende med hundratals eller tusentals ostrukturerade dokument måste den läsa sig igenom allt för att förstå varje gång den ombeds att hjälpa till. En människa som granskar resultatet får lägga ner lika mycket tid på att göra samma sak i omvänd ordning.
AI-profilering förändrar detta. Istället för att betrakta dokument som statiska filer extraherar systemet de juridiska fakta och begrepp som gör dem användbara: ikraftträdandedatum, tillämplig lag, behörig domstol, parter, motpart, domare, klausultyper, skyldigheter, förlängningsvillkor, uppsägningsrättigheter samt alla de verksamhetsspecifika fält som en byrå behöver.
Denna strukturerade information. Genom att profilera ett dokument en gång kan resultatet sedan användas vid alla senare sökningar, översikter, rapporter och i agenternas arbetsflöden. Två byråer kan ha samma dokument och tillgång till samma modeller. Den byrå som har en strukturerad, reglerad och konsekvent extraherad juridisk kontext kommer att uppnå bättre AI-resultat.
2. Sökningen fungerar utifrån betydelse, inte bara utifrån sökord
Advokater vet ofta vilket begrepp de letar efter innan de kommer ihåg de ord som används för att uttrycka det. En transaktionsadvokat kan behöva ett prejudikat med ett undantag för liknande produkter, även om det dokument hon behöver är formulerat på ett annat sätt. En processadvokat kanske minns frågan men inte den exakta formuleringen i inlagan.
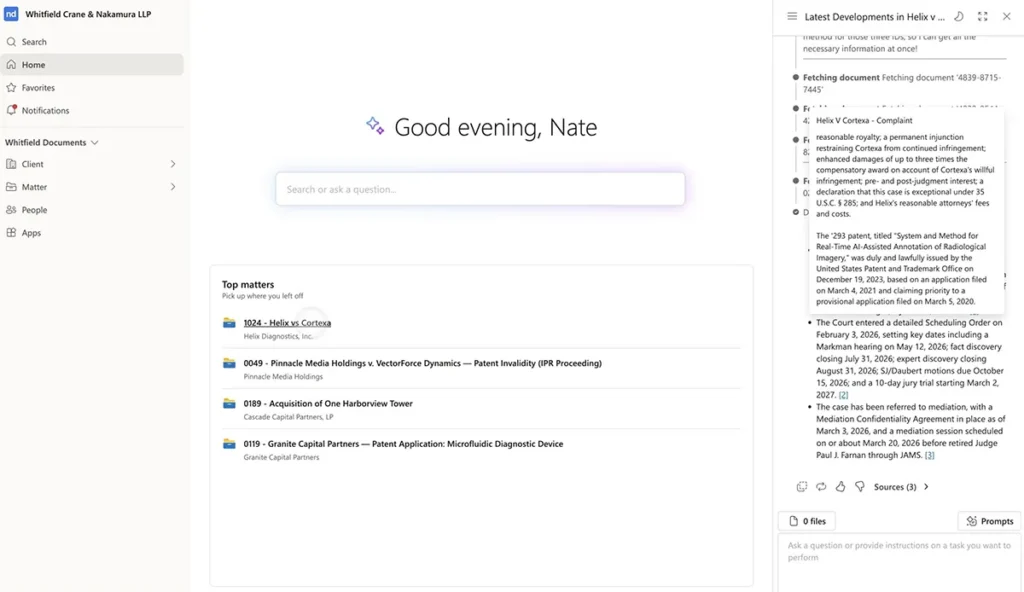
Sökning på nyckelord är fortfarande viktigt. Partnamn, målnummer, hänvisningar till lagtexter och definierade termer kräver precision. Men enbart sökning på nyckelord räcker inte för att få fram den juridiska innebörden när orden ändras.
Ett bättre tillvägagångssätt är hybridsökning: lexikalisk sökning efter exakta termer, semantisk sökning efter begreppsmässig likhet samt metadatafilter för att säkerställa att resultaten är relevanta för rätt ämne, tidsperiod, jurisdiktion, dokumenttyp eller tillämpningsområde.
För jurister innebär det att söka på samma sätt som de tänker. För juridiska AI-agenter innebär det att hämta rätt sammanhang utan att överbelasta kommandoraden med irrelevant material. Bättre informationshämtning innebär mindre ”kontextförorening”, färre förbisedda prejudikat och mer användbara AI-resultat.
3. Det handlar om mer än bara en mapp med dokument
Ett ärende är inte bara ett arbetsutrymme. Det har en struktur. Parter och roller. Krav och invändningar. Förhandlingsskede eller processuell ställning. Viktiga datum. Vittnen. Tvistefrågor. Strategi. Senaste händelser. Relevant rättspraxis. Personer som har arbetat med liknande ärenden tidigare.
I dag är en stor del av detta sammanhang utspritt över dokument, e-postmeddelanden, kalkylblad, anteckningar, tidsrapporter, revisionsspår och juristernas minnen. Sammanhangsgrafen sammanför dessa delar som sökbara noder och relationer ovanpå dokumentgrunden.
Det är just detta som gör det möjligt för en jurist att ta sig an ett ärende och få en överblick över situationen – en bild som vanligtvis måste rekonstrueras manuellt: vilka som är inblandade, vad som har förändrats, vilka handlingar som är relevanta, vad byrån har gjort tidigare och vad man bör fokusera på härnäst.
För enjuridisk AI-agent förändrar detta arbetets ekonomi. Utan grafen måste agenten varje gång den påbörjar ett arbete återuppbygga sammanhanget från grunden. Med grafen kan agenten utgå från ärendets struktur och på ett effektivt sätt ta sig fram till den information som är relevant.
Varför sammanhangetmåste bevaras även efter att sessionen har avslutats
De flesta AI-verktyg arbetar utifrån det som användaren för tillfället matar in: en uppsättning uppladdade dokument, ett sökresultat, en uppmaning eller kontextfönstret för en enskild session. Det kan vara användbart, men det är inte så juridiskt arbete faktiskt fungerar.
Juridiskt arbete bygger på tidigare erfarenheter. Den viktigaste bakgrundsinformationen kan komma från ett tidigare ärende, en redigeringsmarkering från för sex månader sedan, en e-posttråd, ett tidigare beslut av en delägare, en etisk barriär eller en riktlinje från en klient som ändrades igår kväll. Att ladda upp några dokument till en session löser inte det problemet.
En juridisk kontextgraf skiljer sig från andra eftersom den finns där själva arbetet redan finns. Den är integrerad i det primära registersystemet, kopplad till byråns institutionella kunskap och styrs av samma behörigheter, etiska gränser och klientbegränsningar som gäller för själva arbetet.
Varför det är svårt att utveckla detta för juridiska ändamål
Det här är lätt att beskriva men svårt att genomföra.
Juridiska data består till största delen av text, inte av rena databasfält. Betydelsen är nyanserad. En klausul kan verka alldaglig tills ett undantag förändrar risken. En fråga kan avgöras av sambandet mellan en inlaga, ett vittnesmål, ett e-postmeddelande och ett tidigare avgörande. Samma begrepp kan uttryckas på dussintals olika sätt mellan olika byråer, verksamhetsgrupper, rättsområden och dokumenttyper.
Omfattningen är också en annan. Stora advokatbyråer och juridiska avdelningar har inte tiotusen dokument. De har miljontals eller hundratals miljoner dokument, med behörigheter, etiska avgränsningar, klientbegränsningar och aktiviteter som förändras ständigt.
För att en juridisk kontextgraf ska vara användbar måste plattformen kunna extrahera strukturer ur ostrukturerade dokument, indexera innehåll för både exakt och konceptuell sökning, koppla samman dokument över olika ärenden och kommunikationskanaler, säkerställa efterlevnad av styrningsrutiner i realtid samt göra resultaten tillgängliga för både jurister och AI-agenter utan att skapa okontrollerade kopior av byråns data.
Därför harNetDocumentsarbetat i nära samarbete med AWS och Elastic för att ta fram den infrastruktur som krävs för att indexera, hämta och koppla samman juridiska sammanhang i den skala som krävs inom juridiken. Utmaningen ligger inte bara i att bygga en demo som fungerar på ett litet datamaterial. Utmaningen är att få det att fungera i den reglerade, volymkrävande och ansvarsfulla verkligheten inom modern juridisk verksamhet.
Att vara anpassad för juridisk användning innebär mer än att bara lagra fler dokument.
Det innebär att extrahera struktur ur ostrukturerat juridiskt språk, kombinera lexikalisk och semantisk sökning, koppla samman ärenden och kommunikation, tillämpa behörighetskontroller vid sökningstillfället samt göra resultatet användbart för jurister, ombud och nya automatiserade system utan att skapa okontrollerade kopior av byråns data.
| Konstruerad för godkänd våg | |
| Volym | Moderna juridiska organisationer hanterar miljontals eller hundratals miljoner dokument, meddelanden, versioner och ärenderegister. |
| Betydelse | Systemet måste förstå juridiskt språk, inte bara filnamn eller nyckelord. |
| Hämtning | Jurister behöver både precision och förmåga att tänka i begrepp: exakta termer när det är viktigt, och semantiska motsvarigheter när orden skiljer sig åt. |
| Styrelseformer | Varje förfrågan måste följa gällande behörigheter, etiska gränser, kundrestriktioner och riktlinjer för ärendet. |
| Agenter | Samma sammanhang måste kunna användas av både människor och AI-agenter utan att fast kunskap kopieras till isolerade system. |
Det svåra är inte att rita diagrammet. Det svåra är att hålla det uppdaterat, välorganiserat, användbart och tillräckligt snabbt för att passa det sätt på vilket juridiskt arbete faktiskt bedrivs.
Varför styrning måste ske på kontextnivå
I juridiska sammanhang är avsaknaden av styrning inte en tillgång. Det är en risk.
En användbar AI-agent måste veta mer än bara vilken information som finns. Den måste veta om just den här användaren, i just det här ärendet och just nu, har behörighet att använda den. Det omfattar dokumentbehörigheter, etiska gränser, begränsningar baserade på behov av att känna till informationen, riktlinjer för externa rådgivare, kundspecifika AI-policyer samt ändringar på ärendenivå som sker efter det att uppgifterna först skapades.
Det är härarkitekturen spelar en avgörande roll. Om ett AI-verktyg kopierar data till sitt eget system blir styrningen ett synkroniseringsproblem. Varje ändring av behörigheter, policyer eller etiska gränser måste återspeglas någon annanstans. Ur juridisk synvinkel är det inte tillräckligt. Model Context Protocol(MCP) har utvecklats för att tillgodose just detta behov – autentiserad, avgränsad och just-in-time-åtkomst mellan AI och ett registersystem. Genom ett styrt åtkomstlager kanAI-verktyg inom NetDocumentsoch externa verktyg nå samma auktoritativa kontext utan att var och en skapar sin egen, isolerade kopia av företagets kunskap.
Varför NetDocuments har de rätta förutsättningarna för att utveckla det
En juridisk kontextgraf kan inte bara läggas till det juridiska arbetet utifrån. Den måste vara integrerad med de dokument, ärenden, behörigheter, aktiviteter och arbetsflöden som redan styr byråns verksamhet.
Det är därför som dokumenthanteringssystemet är så viktigt. NetDocuments finns redan där juridiska arbetsdokument skapas, lagras, skyddas, söks, hanteras och återanvänds. Plattformen känner till dokumenten. Den känner till ärendena. Den känner till behörigheterna. Den känner till aktiviteten kring arbetet. Och medAI-profilering, begreppsbaserad sökning, ärendekontext och kontrollerad åtkomst via MCP blir denna grund användbar för både jurister och handläggare.
Den strategiska poängen är enkel: många AI-lösningar kommer på ytan att börja se likadana ut. Kvaliteten på det arbete de producerar kommer att bero på det underliggande kontextlagret. En ritningsassistent, en forskningsagent, ett arbetsflödesverktyg eller en autopilot är bara så bra som den juridiska kontext den har tillgång till, och bara så säker som de styrningsramar den följer.
Vilka möjligheter detta öppnar för advokater och ombud
Allt börjar med sammanhanget
En jurist i sitt andra år har tilldelats ett avtalsmål som ska gå till medling. Idag kommer hon kanske att ägna helgen åt att reda ut ärendet: parterna, deras ståndpunkter, tvistefrågorna, handlingarna, den senaste kommunikationen och vad partnern anser vara viktigt.
Med ett grafiskt översiktsverktyg för rättsliga ärenden finns översikten redan tillgänglig. Inte som en statisk sammanfattning, utan som en sammanhängande bild av ärendet: parter, tidslinje, viktiga handlingar, yrkanden eller tvistefrågor, senaste händelser och de personer som tidigare har arbetat med liknande ärenden. Juristen fattar fortfarande sina egna beslut. Hon utgår bara från sammanhanget istället för från ett tomt papper.
Sökningen stämmer överens med advokatens mentala modell
En partner inom fusioner och förvärv kanske inte minns namnet på affären. Han minns däremot affärsfrågan: en kostnadsfördelning som övergår till ersättning från första kronan, förhandlad på företagssidan under de senaste sexton månaderna. Kontextsgrafen gör det möjligt att i sökningen använda begrepp, metadata och ämnesrelationer tillsammans, så att systemet kan hitta relevanta prejudikat istället för att tvinga juristen att minnas de exakta orden.
Institutionell kunskap blir tillgänglig
Företag har i årtionden försökt att dokumentera sin institutionella kunskap. Problemet är att kunskapssystem som är frikopplade från det faktiska arbetet tenderar att förfalla. Kontextsgrafen vänder på logiken. Kunskapen byggs upp utifrån själva arbetet: de dokument, ärenden, meddelanden, aktiviteter och resultat som redan finns i det operativa systemet.
När en erfaren jurist går i pension går det inte att fånga upp allt hon kan. Omdöme är fortfarande omdöme. Men de ärenden hon har drivit, de klausuler hon har förhandlat fram, de strategier hon har valt och det arbetsmaterial hon lämnar efter sig kan bli lättare att hitta, förstå och återanvända.
Agenterna kan göra mer än att bara besvara enstaka frågor
En handläggare som endast tar emot ett fåtal uppladdade dokument kan sammanfatta dessa. En handläggare som är ansluten till byråns styrda kontext kan utföra mer värdefullt arbete: hitta relevanta prejudikat, identifiera rätt utgångspunkt, jämföra ett utkast med byråns riktlinjer, ta fram relaterad korrespondens eller förklara vad som har förändrats i ett ärende sedan användaren senast tittade på det. Det är samma grund som gör autopiloter möjliga: längre, flerstegsarbetsflöden där agenter inte bara svarar på en fråga, utan hjälper till att driva det juridiska arbetet framåt över tid med rätt ärendekontext, behörigheter och skyddsräcken på plats.
Skillnaden ligger inte bara i modellens kvalitet. Det handlar om kontextens kvalitet.
AI-agenter är bara så bra som det juridiska sammanhang de får tillgång till. Modellen spelar roll. Uppgiften spelar roll. Men inom juridiskt arbete är den avgörande frågan ofta om agenten kan nå rätt sammanhang, under rätt styrning och vid rätt tidpunkt.
Registreringssystemet blir ett system för förståelse
I 30 år har juridisk teknik på ett bra sätt dokumenterat vad juristerna har gjort. Nästa steg handlar om att förstå arbetet tillräckligt väl för att kunna hjälpa juristerna med det som kommer härnäst.
Det innebär inte att man ska ersätta juridiska bedömningar. Det innebär istället att man minskar krånglet kring sammanhanget, så att juristerna kan ägna mer tid åt bedömningar, att företräda klienter, förhandlingar, strategiarbete och rådgivning till klienterna.
Grafen över den rättsliga kontexten utgör grunden för denna omställning. Den förvandlar registersystemet till en reglerad källa till institutionell kunskap som jurister och AI-agenter kan använda gemensamt. Den gör arbetet lättare att hitta, mer sammanhängande, enklare att rapportera och bättre förberett för de agentbaserade arbetsflöden som nu börjar ta form.
Framtiden för juridisk AI kommer inte att avgöras av det verktyg som har den största inmatningsrutan. Den kommer att avgöras av den plattform som kan tillhandahålla rätt juridiskt sammanhang, med rätt styrning, just när arbetet pågår.