


rapport: Kontekstgraf for juridisk
Hva er en juridisk kontekstgraf? Og hvorfor juridiske AI-agenter trenger en

Scott Kelly
Visepresident for produkt- og AI-strategi
Juridisk AI har et kontekstproblem
Juridisk AI mislykkes ikke bare fordi en modell får en setning feil. Den mislykkes når den ikke forstår arbeidet den har blitt bedt om å hjelpe med. Den kjenner ikke sakshistorikken. Den vet ikke hvilken presedens som faktisk betyr noe. Den vet ikke hvem som forhandlet frem klausulen, om klienten har begrenset bruken av AI, om en etisk vegg endret seg i går, eller hvorfor ett dokument er viktigere enn et annet.
I juridisk arbeid er ikke disse detaljene bakgrunnsinformasjon. De er arbeidet.
I årevis har advokatfirmaer og juridiske team levd med et kunnskapsproblem som har gjemt seg i det åpne. En ny advokat blir med i en kompleks sak og bruker dager på å rekonstruere kontekst som allerede finnes et sted i firmaet. En partner spør om firmaet har håndtert et lignende problem før, og svaret avhenger av hvem som tilfeldigvis er i rommet. En erfaren advokat går av med pensjon, og flere tiår med vurdering, presedens og praktisk kunnskap blir vanskeligere å få tilgang til.
Den ordningen fungerte da folk var de eneste forbrukerne av firmaets kunnskap. Systemet med arkivering fanget opp arbeidsproduktet. Styringen beskyttet det. Erfarne advokater bar mye av resten i hodet.
AI endrer ligningen. Advokater er ikke lenger de eneste forbrukerne av juridisk kunnskap. AI-assistenter, agenter og nye autopiloter må nå også jobbe med den kunnskapen. Og en agent som ikke kan nå riktig kontekst, jobber i blinde.
Det neste laget med juridisk AI er ikke enda en chatbot. Det er et styrt juridisk kontekstlag: en strukturert, spørrbar, tillatelsesbevisst representasjon av sakene, dokumentene, personene, kommunikasjonen, aktiviteten og de juridiske konseptene som utgjør firmaets institusjonelle kunnskap.
Hva er en graf for juridisk kontekst?
En graf over juridisk kontekst er et levende, styrt kart over juridisk arbeid. Den kobler dokumentene i et firma med sakene de tilhører, personene som jobbet med dem, kommunikasjonen rundt dem, aktiviteten som endret dem, de juridiske konseptene i dem og tillatelsene som styrer hvem som kan bruke dem.
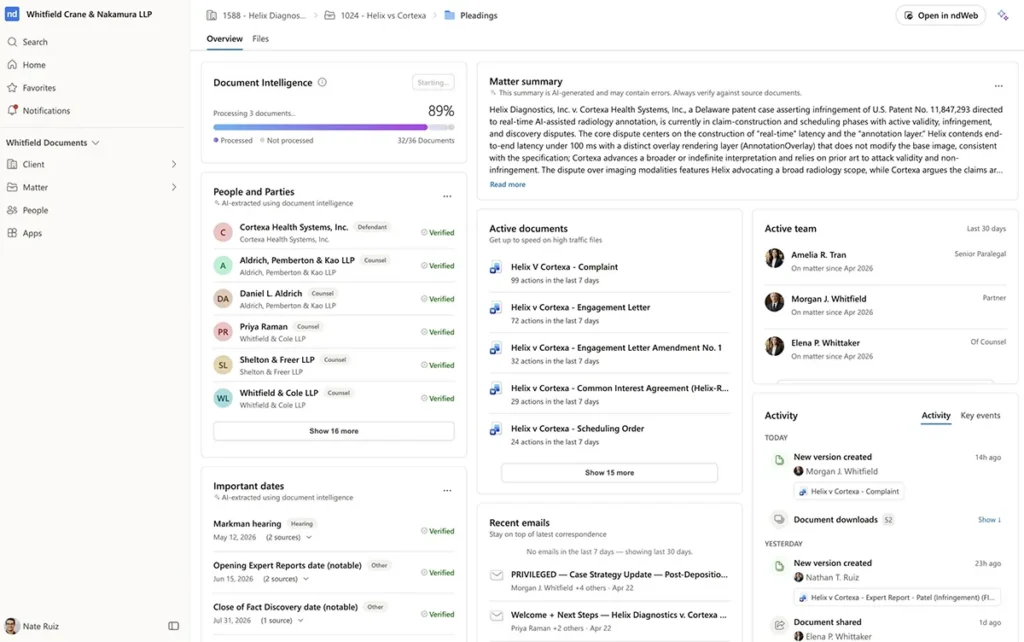
Det er viktig fordi advokater ikke tenker på arbeid som isolerte filer. De tenker i saker, parter, problemstillinger, klausuler, tidslinjer, vitner, forhandlinger, strategi, presedens og risiko. AI-agenter må resonnere ut fra samme kontekst hvis de skal være nyttige.
Et dokumenthåndteringssystem har tradisjonelt besvart et viktig spørsmål: hvor er dokumentet? En graf over juridisk kontekst besvarer et annet spørsmål: hva betyr dette arbeidet, hvordan er det knyttet sammen, hva som er viktig akkurat nå, og hva har denne personen eller agenten lov til å vite?
Fra taksonomi til kontekstgraf
Juridisk AI trenger mer enn en bunke med dokumenter. Den trenger lag med struktur.
En taksonomi (for eksempel nye bransjestandarder som FOLIO , NOS Legal og LMSS ) gir systemet en konsistent måte å klassifisere juridisk arbeid og trekke ut metadataene som er viktige for hver kategori. Når systemet vet at et dokument er en taushetserklæring, leieavtale, klage eller fusjonsavtale, vet det hvilke felt det skal se etter: parter, datoer, gjeldende lov, forpliktelser, krav, klausuler, domstoler, dommere eller andre praksisspesifikke detaljer.
En ontologi definerer hvordan disse konseptene forholder seg. Saker har parter. Parter har roller. Kontrakter inneholder klausuler. Klausuler skaper forpliktelser. Domstoler har dommere. Krav oppstår i henhold til lover. Ontologien er en blåkopi for hvordan juridiske konsepter passer sammen.
En kunnskapsgraf forbinder de faktiske tingene i firmaet: denne saken, denne klienten, denne avtalen, denne motparten, denne dommeren, denne klausulen, denne tidligere forhandlingen, denne advokaten med relevant erfaring.
En kontekstgraf legger til hva juridisk arbeid avhenger mest av: hva som er viktig akkurat nå. Den vet hvilke dokumenter som nylig er endret, hvilken sak som er på vei til mekling, hvilke personer som er aktive, hvilket tidligere arbeid som er relevant, hvem som har tilgang, og hvilke retningslinjer eller etiske grenser som styrer svaret.
Forskjellen er som et statisk kart kontra et sanntidsnavigasjonssystem. Et statisk kart viser veier og kryss. Et navigasjonssystem vet hvor ting er, hvilken rute som er tilgjengelig, hvilken trafikk eller hvilke veisperringer som finnes, og hva som har endret seg siden sist du lette. For juridisk AI er denne sanntidskonteksten forskjellen mellom en agent som søker i dokumenter og en agent som kan hjelpe med juridisk arbeid.
AI-profilering er en av måtene NetDocuments bygger dette fundamentet på. Den gjør ustrukturerte juridiske dokumenter om til strukturerte juridiske data: dokumentklassifiseringer, utvunnede metadata, klausultyper, parter, jurisdiksjoner, gjeldende lov, datoer, forpliktelser og andre konsepter som kan kobles sammen på tvers av saker. Men målet er ikke metadata for metadataenes skyld. Målet er kontekst som en advokat, søkeopplevelse eller AI-agent kan bruke i det øyeblikket arbeidet pågår.
| Progresjonen i ett perspektiv | |
| Taksonomi | Klassifiserer arbeidet og veileder hvilke metadata som skal trekkes ut for hvert dokument eller sakstype. |
| Ontologi | Definerer hvordan juridiske begreper forholder seg: saker har parter, kontrakter inneholder klausuler, klausuler skaper forpliktelser. |
| Kunnskapsgraf | Kobler sammen de faktiske enhetene og dokumentene: denne saken, denne klienten, denne avtalen, denne dommeren, denne advokaten. |
| Kontekstgraf | Legger til den juridiske konteksten i sanntid: hva som har endret seg, hva som er viktig nå, hvem som har tilgang, hvilke retningslinjer som gjelder, og hva en agent trenger før han handler. |
De tre grunnprinsippene for en juridisk kontekstgraf
1. Dokumenter blir strukturerte juridiske data
Juridiske dokumenter uten struktur er en vegg av tekst. Hvis du setter en juridisk AI-agent inn i en sak med hundrevis eller tusenvis av ustrukturerte dokumenter, må den lese seg inn til forståelse hver gang den blir bedt om å hjelpe. Et menneske som gjennomgår resultatet betaler samme kostnad i motsatt rekkefølge.
AI-profilering endrer dette. I stedet for å behandle dokumenter som statiske filer, trekker systemet ut de juridiske faktaene og konseptene som gjør dem nyttige: ikrafttredelsesdatoer, gjeldende lov, jurisdiksjon, parter, motpart, dommer, klausultyper, forpliktelser, fornyelsesvilkår, oppsigelsesrettigheter og hvilke praksisspesifikke felt et firma trenger.
Den utvunnede strukturen blir sammensatt. Profiler et dokument én gang, og hvert senere søk, saksoversikt, rapport og agentarbeidsflyt kan bruke resultatet. To firmaer kan ha de samme dokumentene og tilgang til de samme modellene. Firmaet med strukturert, styrt og konsekvent utvunnet juridisk kontekst vil få bedre AI-resultater.
2. Søk fungerer etter betydning, ikke bare nøkkelord
Advokater kjenner ofte konseptet de leter etter før de husker ordene som brukes for å uttrykke det. En transaksjonsadvokat kan trenge en presedens med et unntak for lignende produkter, selv om dokumentet hun trenger bruker et annet språk. En prosessfullmektig kan huske problemstillingen, men ikke den nøyaktige formuleringen i innlegget.
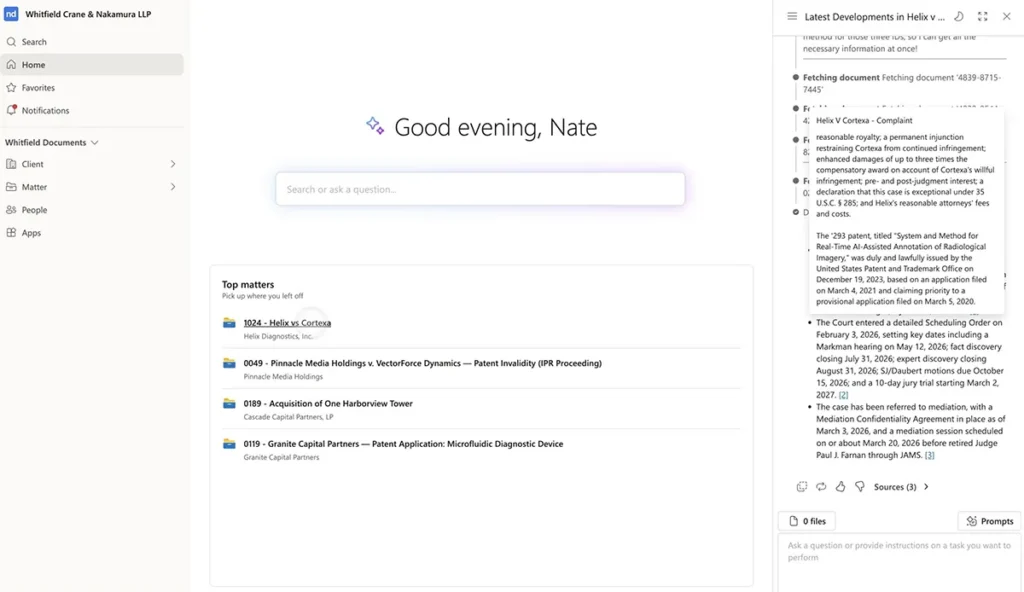
Søk etter nøkkelord er fortsatt viktig. Partsnavn, saksnumre, lovhenvisninger og definerte termer krever presisjon. Men nøkkelordsøk alene kan ikke gjengi juridisk betydning når ordene endres.
Den bedre tilnærmingen er hybridsøk: leksikalsk søk etter eksakte termer, semantisk søk etter konseptuell likhet og metadatafiltre for å holde resultatene forankret i riktig sak, datointervall, jurisdiksjon, dokumenttype eller praksiskontekst.
For advokater betyr det å søke slik de tenker. For juridiske AI-agenter betyr det å hente riktig kontekst uten å oversvømme ledeteksten med irrelevant materiale. Bedre gjenfinning betyr mindre kontekstforurensning, færre tapte presedenser og mer nyttig AI-utdata.
3. Saken blir mer enn en mappe med dokumenter
En sak er ikke bare et arbeidsområde. Den har en form. Parter og roller. Krav og forsvar. Avtalefase eller prosedyremessig stilling. Viktige datoer. Vitner. Saker. Strategi. Nylig aktivitet. Relevant presedens. Personer som har gjort lignende arbeid før.
I dag er mye av denne konteksten spredt utover dokumenter, e-poster, regneark, notater, tidsregistreringer, revisjonsspor og advokaters minner. Kontekstgrafen bringer disse delene sammen som spørrbare noder og relasjoner over dokumentgrunnlaget.
Det er det som lar en advokat åpne en sak og se bildet som vanligvis må rekonstrueres manuelt: hvem som er involvert, hva som har endret seg, hvilke dokumenter som er viktige, hva firmaet har gjort tidligere, og hvor oppmerksomheten bør rettes videre.
For en lovlig AI-agent endrer dette arbeidets økonomi. Uten grafen må en agent bygge opp konteksten fra bunnen av hver gang den begynner å jobbe. Med grafen kan agenten starte fra sakens struktur og bevege seg effektivt til informasjonen som er viktig.
Hvorfor kontekst må vare utover en økt
De fleste AI-verktøy opererer basert på hva en bruker gir dem i øyeblikket: et sett med opplastede dokumenter, et søkeresultat, en ledetekst eller kontekstvinduet for en enkelt økt. Det kan være nyttig, men det er ikke slik juridisk arbeid faktisk fungerer.
Juridisk arbeid er kumulativt. Den viktigste konteksten kan komme fra en tidligere sak, en kritisk tone fra seks måneder siden, en e-posttråd, en partners tidligere avgjørelse, en etisk vegg eller en klientretningslinje som ble endret i går kveld. Å laste opp noen få dokumenter til en økt løser ikke det problemet.
En graf for juridisk kontekst er annerledes fordi den finnes der verket allerede finnes. Den er innebygd i journalsystemet, koblet til firmaets institusjonelle kunnskap og styrt av de samme tillatelsene, etiske grensene og klientrestriksjonene som styrer selve verket.
Hvorfor det er vanskelig å bygge dette for juridiske formål
Dette er lett å beskrive og vanskelig å konstruere.
Juridiske data er for det meste språk, ikke rene databasefelt. Betydningen er nyansert. En klausul kan se vanlig ut inntil unntaket endrer risikoen. En sak kan dreie seg om et forhold mellom et prosesskriv, en vitneforklaring, en e-post og en tidligere avgjørelse. Det samme konseptet kan uttrykkes på en rekke måter på tvers av firmaer, praksisgrupper, jurisdiksjoner og dokumenttyper.
Skalaen er også annerledes. Store advokatfirmaer og juridiske avdelinger har ikke ti tusen dokumenter. De har millioner eller hundrevis av millioner av dokumenter, med tillatelser, etiske grenser, klientbegrensninger og aktivitet som endrer seg kontinuerlig.
For å gjøre en graf over juridisk kontekst nyttig, må plattformen trekke ut struktur fra ustrukturerte dokumenter, indeksere innhold for både nøyaktig og konseptuell gjenfinning, koble sammen poster på tvers av saker og kommunikasjon, håndheve styring i sanntid og gjøre resultatet tilgjengelig for både advokater og AI-agenter uten å lage ukontrollerte kopier av firmaets data.
Derfor samarbeidet NetDocuments tett med AWS og Elastic om infrastrukturen som kreves for å indeksere, hente og koble juridisk kontekst på juridisk skala. Utfordringen er ikke bare å bygge en demo som fungerer på et lite korpus. Utfordringen er å få den til å fungere på tvers av den styrte, store og krevende virkeligheten i moderne juridisk praksis.
Bygget for juridisk skala betyr mer enn å bare lagre flere dokumenter.
Det betyr å trekke ut struktur fra ustrukturert juridisk språk, kombinere leksikalsk og semantisk gjenfinning, koble sammen saker og kommunikasjon, håndheve tillatelser ved spørring og gjøre resultatet brukbart for advokater, agenter og nye autopiloter uten å lage ukontrollerte kopier av firmadata.
| Bygget for lovlig skala | |
| Volum | Moderne juridiske organisasjoner opererer på tvers av millioner eller hundrevis av millioner dokumenter, meldinger, versjoner og saksregister. |
| Betydning | Systemet må forstå juridisk språk, ikke bare filnavn eller nøkkelord. |
| Henting | Advokater trenger både presisjon og konseptuell hukommelse: eksakte termer når de er viktige, semantiske samsvar når ordene er forskjellige. |
| Styring | Enhver forespørsel må respektere gjeldende tillatelser, etiske grenser, klientbegrensninger og saksregler. |
| Agenter | Den samme konteksten må tjene mennesker og AI-agenter uten å kopiere firmakunnskap til frakoblede systemer. |
Det vanskelige er ikke å tegne grafen. Det vanskelige er å holde den levende, styrt, nyttig og rask nok til måten juridisk arbeid faktisk foregår på.
Hvorfor styring må leve på kontekstlaget
I juridisk sammenheng er ikke styring en fordel. Det er en risiko.
En nyttig AI-agent må vite mer enn bare hva slags informasjon som finnes. Den må vite om denne brukeren, i denne saken, i dette øyeblikket, har tillatelse til å bruke den. Dette inkluderer dokumenttillatelser, etiske grenser, restriksjoner for nødvendig kunnskap, retningslinjer for ekstern advokat, klientspesifikke AI-policyer og endringer på saksnivå som skjer etter at dataene først ble opprettet.
Det er her arkitekturen er viktig . Hvis et AI-verktøy kopierer data inn i sitt eget system, blir styring et synkroniseringsproblem. Enhver endring i tillatelser, retningslinjer eller etiske grenser må gjenspeiles et annet sted. I juridisk sammenheng er ikke det godt nok. Model Context Protocol (MCP) har dukket opp for å møte nettopp dette behovet – autentisert, omfangsbestemt, just-in-time-tilgang mellom AI og et arkivsystem. Gjennom et styrt tilgangslag kan AI-verktøy i NetDocuments og eksterne verktøy nå den samme autoritative konteksten uten at hver enkelt oppretter sin egen frakoblede kopi av firmaets kunnskap.
Hvorfor NetDocuments er posisjonert til å bygge det
En graf over juridisk kontekst kan ikke kobles til juridisk arbeid utenfra. Den må ligge tett på dokumentene, sakene, tillatelsene, aktiviteten og arbeidsflytene som allerede definerer hvordan firmaet opererer.
Derfor er systemet for arkivering viktig. NetDocuments ligger allerede der juridiske arbeidsprodukter opprettes, lagres, sikres, søkes i, styres og gjenbrukes. Plattformen kjenner dokumentene. Den kjenner sakene. Den kjenner tillatelsene. Den kjenner aktiviteten rundt arbeidet. Og med AI-profilering , konseptbasert søk, sakskontekst og styrt tilgang gjennom MCP, blir dette grunnlaget brukbart av både advokater og agenter.
Det strategiske poenget er enkelt: mange AI-opplevelser vil begynne å se like ut på overflaten. Kvaliteten på arbeidet de produserer vil avhenge av kontekstlaget under. En utkastassistent, researchagent, arbeidsflytverktøy eller autopilot er bare så god som den juridiske konteksten den kan nå, og bare så sikker som styringen den respekterer.
Hva dette åpner opp for advokater og agenter
Enhver sak starter med kontekst
En andreårsmedarbeider er ansatt med en kontraktstvist som er på vei til mekling. I dag kan hun bruke helgen på å rekonstruere saken: parter, holdning, problemer, dokumenter, nylig kommunikasjon og hva partneren mener er viktig.
Med en graf over juridisk kontekst er saksoversikten allerede der. Ikke som et statisk sammendrag, men som en sammenhengende visning av saken: parter, tidslinje, viktige dokumenter, krav eller problemer, nylig aktivitet og personer som har gjort lignende arbeid før. Medarbeideren utøver fortsatt dømmekraft. Hun starter bare fra kontekst i stedet for et blankt ark.
Søket samsvarer med advokatens mentale modell
En fusjons- og oppkjøpspartner husker kanskje ikke avtalenavnet. Han husker forretningsproblemet: en tipping-kurv som snus til første dollar-gjenoppretting, forhandlet på selskapssiden, i løpet av de siste seksten månedene. Kontekstgrafen lar søk bruke konseptene, metadataene og saksforholdene sammen, slik at systemet kan returnere den relevante presedensen i stedet for å tvinge advokaten til å huske de nøyaktige ordene.
Institusjonell kunnskap blir tilgjengelig
Bedrifter har forsøkt å fange opp institusjonell kunnskap i flere tiår. Problemet er at kunnskapssystemer atskilt fra arbeidet har en tendens til å forfalle. Kontekstgrafen reverserer geometrien. Kunnskapen er bygd opp fra selve arbeidet: dokumentene, sakene, kommunikasjonen, aktiviteten og resultatene som allerede finnes i arkivsystemet.
Når en erfaren advokat går av med pensjon, kan ikke alt hun vet fanges opp. Vurdering er fortsatt vurdering. Men sakene hun formet, klausulene hun forhandlet frem, strategiene hun valgte og arbeidsproduktet hun etterlot seg, kan bli lettere å finne, forstå og gjenbruke.
Agenter kan gjøre mer enn å svare på isolerte spørsmål
En agent som bare mottar noen få opplastede dokumenter, kan oppsummere disse dokumentene. En agent som er koblet til firmaets styrte kontekst, kan gjøre mer nyttig arbeid: finne relevant presedens, identifisere riktig utgangspunkt, sammenligne et utkast med firmaets strategi, avdekke relatert kommunikasjon eller forklare hva som har endret seg i en sak siden brukeren sist så. Det samme grunnlaget er det som gjør autopiloter mulige: mer langvarige arbeidsflyter i flere trinn der agenter ikke bare svarer på et spørsmål, men bidrar til å flytte juridisk arbeid fremover over tid med riktig sakskontekst, tillatelser og sikkerhetstiltak på plass.
Forskjellen er ikke bare modellkvalitet. Det er kontekstkvalitet.
AI-agenter er bare så gode som den juridiske konteksten som leveres til dem. Modellen er viktig. Prompten er viktig. Men i juridisk arbeid er det avgjørende spørsmålet ofte om agenten kan nå riktig kontekst, under riktig styring, til riktig tid.
Registreringssystemet blir et forståelsessystem
I 30 år har juridisk teknologi gjort en god jobb med å lagre det advokater gjorde. Neste kapittel handler om å forstå arbeidet godt nok til å hjelpe advokater med å gjøre det som kommer etterpå.
Det betyr ikke å erstatte juridisk dømmekraft. Det betyr å redusere friksjonen rundt kontekst, slik at advokater kan bruke mer tid på dømmekraft, advokatvirksomhet, forhandlinger, strategi og klientrådgivning.
Den juridiske kontekstgrafen er grunnlaget for dette skiftet. Den gjør journalsystemet til en styrt kilde til institusjonell kunnskap som advokater og AI-agenter kan bruke sammen. Den gjør arbeidet lettere å finne, mer tilkoblet, mer rapporterbart og mer klart for de agentiske arbeidsflytene som begynner å komme.
Fremtiden for juridisk AI vil ikke vinnes av verktøyet med den største promptboksen. Den vil vinnes av plattformen som kan levere den rette juridiske konteksten, med riktig styring, når arbeidet skjer.