


rapport : Graphique contextuel pour le domaine juridique
Qu'est-ce qu'un graphe de contexte juridique ? Et pourquoi les agents d'IA juridique en ont-ils besoin ?

Scott Kelly
Vice-président chargé de la stratégie produit et IA
L'IA juridique se heurte à un problème de contexte
L'IA juridique n'échoue pas simplement parce qu'un modèle se trompe sur une phrase. Elle échoue lorsqu'elle ne comprend pas le dossier sur lequel on lui demande d'intervenir. Elle ne connaît pas l'historique de l'affaire. Elle ne sait pas quels précédents sont réellement pertinents. Elle ignore qui a négocié la clause, si le client a imposé des restrictions à l'utilisation de l'IA, si une barrière éthique a été modifiée hier, ou pourquoi un document a plus d'importance qu'un autre.
Dans le domaine juridique, ces détails ne constituent pas de simples informations contextuelles. Ils constituent le cœur même du travail.
Depuis des années, les cabinets d'avocats et les équipes juridiques sont confrontés à un problème de connaissances qui se cache sous leurs yeux. Lorsqu'un nouvel associé rejoint une affaire complexe, il passe des jours à reconstituer un contexte qui existe pourtant déjà quelque part au sein du cabinet. Lorsqu'un associé demande si le cabinet a déjà traité un dossier similaire, la réponse dépend de qui se trouve dans la pièce. Lorsqu'un avocat chevronné prend sa retraite, des décennies de jugement, de jurisprudence et de savoir-faire deviennent plus difficiles à mettre à profit.
Ce système fonctionnait lorsque les collaborateurs étaient les seuls à avoir accès aux connaissances de l'entreprise. Le système d'archivage enregistrait les résultats du travail. La gouvernance en assurait la protection. Quant au reste, les avocats expérimentés le gardaient en grande partie en mémoire.
L'IA change la donne. Les avocats ne sont plus les seuls à avoir besoin de connaissances juridiques. Les assistants, agents et systèmes de pilotage automatique émergents basés sur l'IA doivent désormais eux aussi exploiter ces connaissances. Et un agent qui ne parvient pasà cerner le contexte appropriétravaille à l'aveuglette.
La prochaine étape dans le domaine de l'IA juridique ne consiste pas en un simple chatbot. Il s'agit d'une couche contextuelle juridique régie par des règles : une représentation structurée, consultable et respectueuse des autorisations, qui englobe les dossiers, les documents, les personnes, les communications, les activités et les concepts juridiques constituant le savoir institutionnel du cabinet.
Qu'est-ce qu'un graphe de contexte juridique ?
Un graphe contextuel juridiqueest une représentation dynamique et structurée du travail juridique. Il relie les documents d'un cabinet aux dossiers auxquels ils se rapportent, aux personnes qui y ont travaillé, aux communications qui s'y rapportent, aux modifications qui y ont été apportées, aux concepts juridiques qu'ils contiennent et aux autorisations qui déterminent qui peut les utiliser.
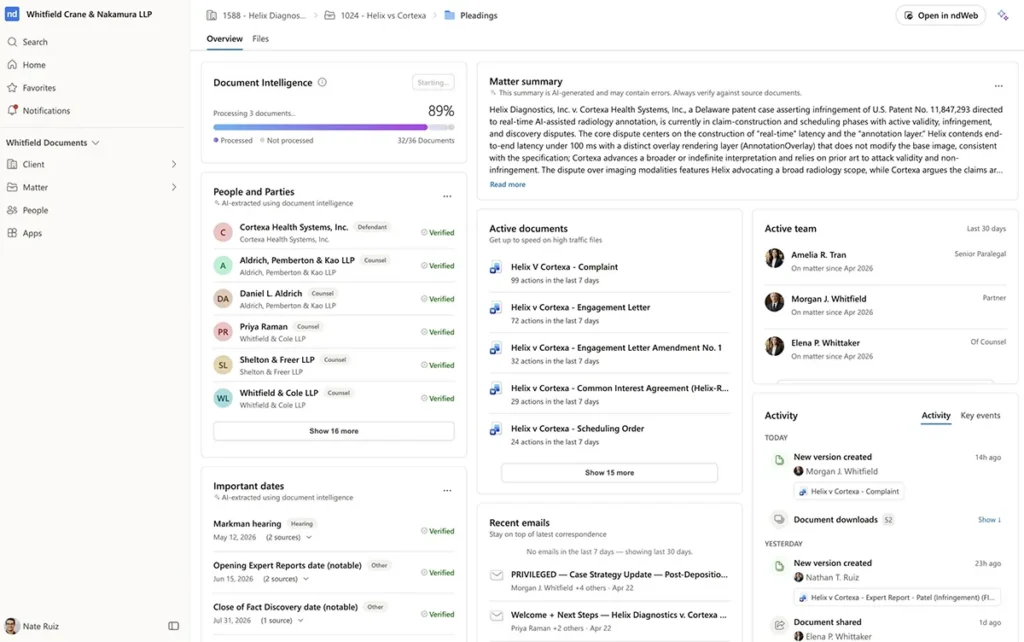
Cela est important car les avocats ne considèrent pas leur travail comme une succession de dossiers isolés. Ils raisonnent en termes de dossiers, de parties, de questions en jeu, de clauses, de délais, de témoins, de négociations, de stratégie, de jurisprudence et de risques. Pour être utiles, les agents d'IA doivent raisonner à partir de ce même contexte.
Un système de gestion documentairerépondait traditionnellement à une question essentielle : où se trouve le document ? Un graphe contextuel juridique répond à une autre question : que signifie ce document, quels sont ses liens, qu'est-ce qui importe à l'heure actuelle, et qu'est-ce que cette personne ou cet agent est autorisé à savoir ?
De la taxonomie au graphe contextuel
L'IA juridique ne se contente pas d'une simple pile de documents. Elle a besoin d'une structure à plusieurs niveaux.
Une taxonomie (par exemple, les normes émergentes du secteur telles queFOLIO,NOS Legal etLMSS) permet au système de classer de manière cohérente les travaux juridiques et d'extraire les métadonnées pertinentes pour chaque catégorie. Une fois que le système a identifié qu'un document est un accord de confidentialité, un bail, une plainte ou un accord de fusion, il sait quels champs rechercher : les parties, les dates, le droit applicable, les obligations, les revendications, les clauses, les tribunaux, les juges ou d'autres détails spécifiques à la pratique.
Une ontologie définit les relations entre ces concepts. Les affaires impliquent des parties. Les parties ont des rôles. Les contrats contiennent des clauses. Les clauses créent des obligations. Les tribunaux sont composés de juges. Les actions en justice découlent de la législation. L'ontologie est le schéma qui décrit comment les concepts juridiques s'articulent entre eux.
Un graphe de connaissances relie les différents éléments concrets au sein de l'entreprise : cette affaire, ce client, ce contrat, cette contrepartie, ce juge, cette clause, cette négociation antérieure, cet avocat possédant l'expérience requise.
Un graphe contextuel apporte ce dont le travail juridique a le plus besoin : ce qui compte à l'instant présent. Il sait quels documents ont été modifiés récemment, quelle affaire va faire l'objet d'une médiation, quelles personnes sont impliquées, quels travaux antérieurs sont pertinents, qui y a accès, et quelles politiques ou barrières éthiques régissent la réponse.
La différence est comparable à celle entre une carte statique et un système de navigation en temps réel. Une carte statique indique les routes et les intersections. Un système de navigation, lui, sait où se trouvent les lieux, quels itinéraires sont disponibles, quels sont les embouteillages ou les barrages routiers, et ce qui a changé depuis votre dernière consultation. Dans le domaine de l'IA juridique, ce contexte en temps réel fait toute la différence entre un agent qui se contente de rechercher des documents et un agent capable d'apporter une aide concrète dans le travail juridique.
Le profilage par IA est l'un des moyens par lesquels NetDocuments pose ces bases. Il transforme des documents juridiques non structurés en données juridiques structurées : classifications de documents, métadonnées extraites, types de clauses, parties, juridictions, droit applicable, dates, obligations et autres concepts pouvant être mis en relation d'un dossier à l'autre. Mais l'objectif n'est pas de générer des métadonnées pour le simple plaisir de le faire. L'objectif est de fournir un contexte qu'un avocat, un outil de recherche ou un agent IA puisse exploiter au moment même où le travail s'effectue.
| La progression en un coup d'œil | |
| Taxonomie | Définit la classification des travaux et indique quelles métadonnées doivent être extraites pour chaque type de document ou de dossier. |
| Ontologie | Définit les relations entre les concepts juridiques : les affaires impliquent des parties, les contrats contiennent des clauses, et les clauses créent des obligations. |
| Graphique de connaissances | Relie les entités et les enregistrements concrets : cette affaire, ce client, ce contrat, ce juge, cet avocat. |
| Graphique de contexte | Fournit le contexte juridique actuel : ce qui a changé, ce qui importe aujourd’hui, qui y a accès, quelle politique s’applique et de quoi un agent a besoin avant d’agir. |
Les trois piliers d'un graphe de contexte juridique
1. Les documents sont transformés en données juridiques structurées
Les documents juridiques dépourvus de structure ne sont qu'un long bloc de texte. Lorsqu'on confie à un agent IA juridique un dossier contenant des centaines, voire des milliers de documents non structurés, celui-ci doit se plonger dans le texte pour en saisir le sens à chaque fois qu'on lui demande de fournir une aide. Un humain chargé de vérifier le résultat doit, à son tour, fournir un effort équivalent.
Le profilage par IA change la donne. Au lieu de considérer les documents comme des fichiers statiques, le système en extrait les faits et concepts juridiques qui les rendent utiles : dates d'entrée en vigueur, droit applicable, juridiction compétente, parties, contrepartie, juge, types de clauses, obligations, conditions de renouvellement, droits de résiliation, ainsi que tous les champs spécifiques à la pratique dont un cabinet a besoin.
Ces composantes de structure extraites. Il suffit de profiler un document une seule fois pour que chaque recherche ultérieure, chaque synthèse, chaque rapport et chaque workflow des agents puisse exploiter ce résultat. Deux cabinets peuvent disposer des mêmes documents et avoir accès aux mêmes modèles. Le cabinet qui dispose d'un contexte juridique structuré, réglementé et extrait de manière cohérente obtiendra de meilleurs résultats en matière d'IA.
2. La recherche s'effectue en fonction du sens, et pas seulement à partir de mots-clés
Les avocats connaissent souvent le concept qu’ils recherchent avant même de se souvenir des termes utilisés pour l’exprimer. Une avocate spécialisée en droit des transactions peut avoir besoin d’un précédent comportant une clause d’exclusion pour les produits similaires, même si le document dont elle a besoin utilise une formulation différente. Un avocat plaidant peut se souvenir du problème, mais pas de la formulation exacte utilisée dans le mémoire.
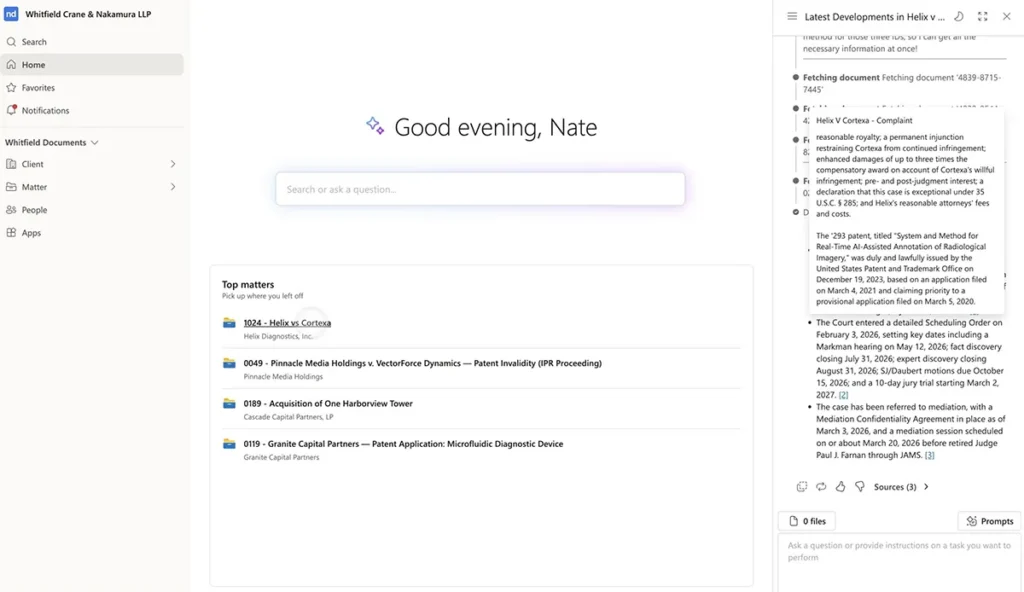
La recherche par mots-clés reste importante. Les noms des parties, les numéros de dossier, les références législatives et les termes définis exigent de la précision. Mais la recherche par mots-clés ne suffit pas à elle seule à restituer le sens juridique lorsque les termes changent.
La meilleure approche consiste à recourir à une recherche hybride : une recherche lexicale pour les termes exacts, une recherche sémantique pour la similitude conceptuelle, ainsi que des filtres de métadonnées permettant de restreindre les résultats au sujet, à la période, à la juridiction, au type de document ou au contexte pratique souhaités.
Pour les avocats, cela implique de rechercher en fonction de leur mode de pensée. Pour les agents d'IA juridiques, cela signifie extraire le bon contexte sans surcharger la requête avec des informations non pertinentes. Une meilleure extraction se traduit par moins de « pollution contextuelle », moins de précédents manqués et des résultats d'IA plus utiles.
3. L'affaire ne se résume plus à un simple dossier de documents
Une affaire n'est pas seulement un espace de travail. Elle a une structure bien définie. Elle comporte des parties et des rôles. Des demandes et des moyens de défense. Elle se situe à un certain stade de la procédure ou présente une situation procédurale particulière. Elle comporte des dates clés, des témoins, des points litigieux, une stratégie, des activités récentes, des précédents pertinents, ainsi que des personnes ayant déjà traité des dossiers similaires.
Aujourd'hui, une grande partie de ce contexte est dispersée entre divers documents, e-mails, feuilles de calcul, notes, relevés de temps, pistes d'audit et souvenirs des avocats. Le graphe de contexte rassemble ces éléments sous forme de nœuds et de relations interrogeables, au-dessus de la base documentaire.
C'est ce qui permet à un avocat d'ouvrir un dossier et d'avoir une vue d'ensemble de la situation, qu'il faudrait normalement reconstituer manuellement : qui est concerné, quels sont les changements intervenus, quels documents sont pertinents, quelles actions le cabinet a déjà menées et sur quoi il convient de se concentrer ensuite.
Pour unagent d'IA juridique, cela modifie la dynamique du travail. Sans le graphe, chaque fois qu'un agent commence à travailler, il doit reconstituer le contexte à partir de zéro. Grâce au graphe, l'agent peut partir de la structure du dossier et accéder efficacement aux informations pertinentes.
Pourquoi le contextedoit-il perdurer au-delà d'une session?
La plupart des outils d'IA fonctionnent à partir de ce que l'utilisateur leur fournit sur le moment : un ensemble de documents téléchargés, un résultat de recherche, une invite ou la fenêtre de contexte d'une session donnée. Cela peut s'avérer utile, mais ce n'est pas ainsi que se déroule réellement le travail juridique.
Le travail juridique est un processus cumulatif. Le contexte le plus important peut provenir d’une affaire antérieure, d’une version annotée datant de six mois, d’un fil de discussion par e-mail, d’une décision prise précédemment par un associé, d’une barrière éthique ou d’une directive du client qui a changé hier soir. Le simple fait de télécharger quelques documents dans une session ne résout pas ce problème.
Un graphe contextuel juridique se distingue par le fait qu’il s’intègre directement à l’environnement où le travail est déjà effectué. Il est intégré au système de référence, relié au savoir institutionnel du cabinet et régi par les mêmes autorisations, barrières éthiques et restrictions liées aux clients que celles qui s’appliquent au travail lui-même.
Pourquoi il est difficile de mettre cela en place pour le service juridique
C'est facile à décrire, mais difficile à mettre en œuvre.
Les données juridiques sont principalement constituées de texte, et non de champs de base de données bien structurés. Leur sens est nuancé. Une clause peut paraître banale jusqu’à ce qu’une exception vienne modifier le risque. L’issue d’une affaire peut dépendre d’un lien entre un acte de procédure, une déposition, un courriel et une décision antérieure. Un même concept peut être exprimé de dizaines de façons différentes selon les cabinets, les groupes de pratique, les juridictions et les types de documents.
L'échelle est également différente. Les grands cabinets d'avocats et les services juridiques ne gèrent pas seulement dix mille documents. Ils gèrent des millions, voire des centaines de millions de dossiers, avec des autorisations d'accès, des barrières éthiques, des restrictions liées aux clients et des activités en constante évolution.
Pour qu'un graphe contextuel juridique soit utile, la plateforme doit extraire la structure de documents non structurés, indexer le contenu en vue d'une recherche à la fois littérale et conceptuelle, relier les dossiers entre eux au-delà des dossiers et des communications, assurer la gouvernance en temps réel et mettre les résultats à la disposition des avocats et des agents IA sans créer de copies incontrôlées des données du cabinet.
C'est pourquoiNetDocumentsa collaboré étroitement avec AWS et Elastic pour mettre en place l'infrastructure nécessaire à l'indexation, à la recherche et à la mise en relation du contexte juridique à l'échelle du secteur juridique. Le défi ne consiste pas simplement à créer une démonstration fonctionnant sur un petit corpus. Il s'agit de garantir son efficacité dans le contexte réel de la pratique juridique moderne, caractérisé par une réglementation stricte, des volumes importants et des enjeux considérables.
Une solutionconçue pour répondre aux exigences légales ne se limite pas à un simple stockage de documents.
Cela implique d'extraire la structure d'un langage juridique non structuré, de combiner la recherche lexicale et sémantique, de relier les dossiers et les communications, d'appliquer les autorisations au moment de la requête, et de rendre le résultat exploitable par les avocats, les agents et les systèmes automatisés émergents sans créer de copies incontrôlées des données du cabinet.
| Conçu pour une utilisation à échelle légale | |
| Volume | Les cabinets d'avocats modernes gèrent des millions, voire des centaines de millions de documents, de messages, de versions et de dossiers. |
| Signification | Le système doit comprendre le langage juridique, et pas seulement les noms de fichiers ou les mots-clés. |
| Récupération | Les avocats doivent faire preuve à la fois de précision et d'une bonne mémoire conceptuelle : ils doivent employer des termes exacts lorsque cela s'impose, et rechercher des équivalents sémantiques lorsque les mots diffèrent. |
| Gouvernance | Toute demande doit respecter les autorisations en vigueur, les barrières éthiques, les restrictions imposées par les clients et les politiques relatives aux dossiers. |
| Agents | Ce même contexte doit pouvoir servir à la fois aux utilisateurs et aux agents IA sans qu'il soit nécessaire de dupliquer les connaissances de l'entreprise dans des systèmes isolés. |
Le plus difficile n'est pas de tracer le graphique. Le plus difficile est de le maintenir à jour, bien géré, utile et suffisamment rapide pour s'adapter au rythme réel du travail juridique.
Pourquoi la gouvernance doit s'inscrire au niveau du contexte
Dans le domaine juridique, l'absence de gouvernance n'est pas un atout. C'est un risque.
Un agent IA performant ne doit pas se contenter de savoir quelles informations existent. Il doit également savoir si l'utilisateur concerné, dans le cadre de ce dossier et à ce moment précis, est autorisé à y accéder. Cela inclut les autorisations d'accès aux documents, les barrières éthiques, les restrictions liées au besoin d'en connaître, les directives relatives aux conseillers externes, les politiques IA spécifiques aux clients, ainsi que les modifications apportées au niveau du dossier après la création initiale des données.
C'est là quel'architecture prend toute son importance. Si un outil d'IA copie des données dans son propre système, la gouvernance se transforme en un problème de synchronisation. Chaque modification apportée aux autorisations, aux politiques ou aux barrières éthiques doit être répercutée ailleurs. Sur le plan juridique, cela n'est pas suffisant. Le Model Context Protocol(MCP) a été conçu pour répondre précisément à ce besoin : un accès authentifié, délimité et en temps réel entre l’IA et un système d’enregistrement. Grâce à une couche d’accès régie,les outils d’IA au sein de NetDocumentset les outils externes peuvent accéder au même contexte faisant autorité sans que chacun ne crée sa propre copie déconnectée des connaissances du cabinet.
Pourquoi NetDocuments est bien placé pour le développer
Un graphe contextuel juridique ne peut pas être simplement greffé de l'extérieur sur le travail juridique. Il doit être étroitement lié aux documents, aux dossiers, aux autorisations, aux activités et aux flux de travail qui définissent déjà le mode de fonctionnement du cabinet.
C'est pourquoi le système d'archivage officiel revêt une importance capitale. NetDocuments s'intègre déjà là où les documents juridiques sont créés, stockés, sécurisés, recherchés, gérés et réutilisés. La plateforme connaît les documents. Elle connaît les dossiers. Elle connaît les autorisations. Elle connaît l'activité liée au travail. Et grâceau profilage par IA, à la recherche par concepts, au contexte des dossiers et à l'accès contrôlé via MCP, cette base devient exploitable tant par les avocats que par les agents.
Le principe stratégique est simple : de nombreuses applications d'IA commenceront à se ressembler en apparence. La qualité du travail qu'elles produisent dépendra de la couche contextuelle sous-jacente. Un assistant de rédaction, un agent de recherche, un outil de gestion des flux de travail ou un système de pilotage automatique ne vaut que par la qualité du contexte juridique auquel il a accès, et n'est sûr que dans la mesure où il respecte les règles de gouvernance.
Ce que cela offre aux avocats et aux agents
Tout commence par le contexte
Une collaboratrice en deuxième année a été affectée à un litige contractuel qui va être soumis à la médiation. Aujourd’hui, elle va peut-être passer le week-end à faire le point sur l’affaire : les parties, leurs positions, les enjeux, les documents, les communications récentes et ce que l’associé juge important.
Grâce à un graphique contextuel juridique, la vue d'ensemble du dossier est déjà disponible. Il ne s'agit pas d'un résumé statique, mais d'une vue d'ensemble articulée du dossier : les parties, le calendrier, les documents clés, les demandes ou les points litigieux, les activités récentes et les personnes ayant déjà traité des dossiers similaires. La collaboratrice continue d'exercer son jugement. Elle part simplement du contexte plutôt que d'une page blanche.
La recherche correspond au modèle mental de l'avocat
Un associé spécialisé en fusions-acquisitions ne se souvient peut-être pas du nom de l'opération. Ce dont il se souvient, c'est l'enjeu commercial : un barème dégressif passant à un recouvrement dès le premier dollar, négocié du côté de l'entreprise au cours des seize derniers mois. Le graphe contextuel permet au moteur de recherche d'exploiter conjointement les concepts, les métadonnées et les relations entre les dossiers, de sorte que le système puisse renvoyer le précédent pertinent sans obliger l'avocat à se souvenir des termes exacts.
Le savoir institutionnel devient accessible
Depuis des décennies, les entreprises s'efforcent de capitaliser sur le savoir institutionnel. Le problème est que les systèmes de connaissances dissociés du travail ont tendance à se dégrader. Le graphe contextuel renverse cette dynamique. La connaissance se construit à partir du travail lui-même : les documents, les dossiers, les communications, les activités et les résultats qui existent déjà dans le système d'enregistrement.
Lorsqu'une avocate chevronnée prend sa retraite, il n'est pas possible de consigner tout ce qu'elle sait. Le jugement reste une question de jugement. Mais les dossiers qu'elle a menés à bien, les clauses qu'elle a négociées, les stratégies qu'elle a choisies et les documents qu'elle a laissés peuvent devenir plus faciles à trouver, à comprendre et à réutiliser.
Les agents peuvent faire bien plus que simplement répondre à des questions ponctuelles
Un agent qui ne reçoit que quelques documents téléchargés peut se contenter de les résumer. Un agent connecté au contexte réglementé du cabinet peut accomplir des tâches plus utiles : trouver des précédents pertinents, identifier le bon point de départ, comparer un projet au guide de procédure du cabinet, faire remonter les communications associées ou expliquer ce qui a changé dans un dossier depuis la dernière consultation de l'utilisateur. C'est cette même base qui rend possible l'utilisation des pilotes automatiques : des workflows plus longs et en plusieurs étapes où les agents ne se contentent pas de répondre à une question, mais contribuent à faire avancer le travail juridique au fil du temps, en s'appuyant sur le contexte approprié du dossier, les autorisations nécessaires et des garde-fous bien définis.
La différence ne réside pas seulement dans la qualité du modèle. Elle réside aussi dans la qualité du contexte.
La qualité des agents IA dépend entièrement du contexte juridique qui leur est fourni. Le modèle a son importance. La consigne a son importance. Mais dans le domaine juridique, la question décisive est souvent de savoir si l'agent est capable d'accéder au bon contexte, dans le cadre d'une gouvernance appropriée, au moment opportun.
Le système d'enregistrement devient un système de compréhension
Depuis 30 ans, les technologies juridiques ont su parfaitement consigner le travail des avocats. La prochaine étape consiste à comprendre suffisamment bien ce travail pour aider les avocats à passer à l'étape suivante.
Cela ne signifie pas pour autant de se substituer au jugement juridique. Il s'agit plutôt de réduire les obstacles liés au contexte afin que les avocats puissent consacrer davantage de temps à l'analyse juridique, à la défense des intérêts, à la négociation, à l'élaboration de stratégies et au conseil aux clients.
Le graphe du contexte juridique constitue le fondement de cette évolution. Il transforme le système d'enregistrement en une source contrôlée de connaissances institutionnelles que les juristes et les agents d'IA peuvent exploiter conjointement. Il rend le travail plus facile à trouver, mieux interconnecté, plus facile à documenter et mieux préparé pour les flux de travail automatisés qui commencent à voir le jour.
Ce n'est pas l'outil doté de la plus grande zone de saisie qui s'imposera dans le domaine de l'IA juridique. Ce sera la plateforme capable de fournir le contexte juridique approprié, assorti d'une gouvernance adéquate, au moment même où le travail est effectué.